Как установить Apache Hadoop на CentOS 8
В этом руководстве мы покажем вам, как установить Apache Hadoop на CentOS 8. Для тех из вас, кто не знал, Apache Hadoop — это платформа с открытым исходным кодом, используемая для распределенного хранения, а также для распределенной обработки больших данных в кластерах компьютеры, работающие на стандартном оборудовании. Вместо того, чтобы полагаться на оборудование для обеспечения высокой доступности, сама библиотека предназначена для обнаружения и обработки сбоев на уровне приложений, таким образом предоставляя услуги высокой доступности поверх кластера компьютеров, каждый из которых может быть подвержен сбоям.
В этой статье предполагается, что у вас есть хотя бы базовые знания Linux, вы знаете, как использовать оболочку, и, что наиболее важно, вы размещаете свой сайт на собственном VPS. Установка довольно проста и предполагает, что вы работаете с учетной записью root, в противном случае вам может потребоваться добавить ‘ sudo‘ к командам для получения привилегий root. Я покажу вам пошаговую установку Apache Hadoop на сервере CentOS 8.
Установите Apache Hadoop на CentOS 8
Шаг 1. Во-первых, давайте начнем с проверки актуальности вашей системы.
sudo dnf update
Шаг 2. Установка Java.
Apache Hadoop написан на Java и поддерживает только версию Java 8. Вы можете установить OpenJDK 8 с помощью следующей команды:
sudo dnf install java-1.8.0-openjdk ant
Проверьте версию Java:
java -version
Шаг 3. Установка Apache Hadoop CentOS 8.
Рекомендуется создать обычного пользователя для настройки Apache Hadoop, создать пользователя с помощью следующей команды:
useradd hadoop passwd hadoop
Далее нам нужно будет настроить SSH-аутентификацию без пароля для локальной системы:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 640 ~/.ssh/authorized_keys
Проверьте конфигурацию ssh без пароля с помощью команды:
ssh localhost
Следующие шаги, загрузите последнюю стабильную версию Apache Hadoop. На момент написания этой статьи это версия 3.2.1:
wget http://apachemirror.wuchna.com/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz tar -xvzf hadoop-3.2.1.tar.gz mv hadoop-3.2.1 hadoop
Затем вам нужно будет настроить Hadoop и переменные среды Java в вашей системе:
nano ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Теперь мы активируем переменные среды с помощью следующей команды:
source ~/.bashrc
Затем откройте файл переменной среды Hadoop:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/
Hadoop имеет множество файлов конфигурации, которые необходимо настроить в соответствии с требованиями вашей инфраструктуры Hadoop. Начнем с конфигурации с базовой настройкой кластера с одним узлом Hadoop:
cd $HADOOP_HOME/etc/hadoop
Отредактируйте core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Редактировать :hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Редактировать :mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Отредактируйте yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Теперь отформатируйте namenode с помощью следующей команды, не забудьте проверить каталог хранилища:
hdfs namenode -format
Запустите демоны NameNode и DataNode с помощью скриптов, предоставленных Hadoop:
start-dfs.sh
Шаг 4. Настройте брандмауэр.
Выполните следующую команду, чтобы разрешить подключения Apache Hadoop через брандмауэр:
firewall-cmd --permanent --add-port=9870/tcp firewall-cmd --permanent --add-port=8088/tcp firewall-cmd --reload
Шаг 5. Доступ к Apache Hadoop.
По умолчанию Apache Hadoop будет доступен через HTTP-порт 9870 и порт 50070. Откройте свой любимый браузер и перейдите по адресу http://your-domain.com:9870 или http: // your-server-ip: 9870.
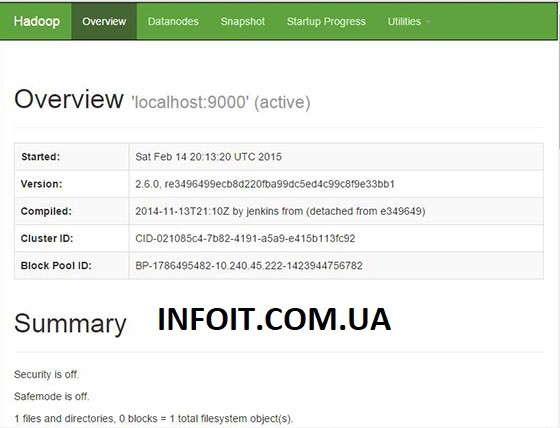
Поздравляю! Вы успешно установили Apache Hadoop . Благодарим за использование этого руководства для установки Hadoop в системе CentOS 8. Для получения дополнительной помощи или полезной информации мы рекомендуем вам посетить официальный веб-сайт Apache Hadoop .